A primer on the original Transformer model architecture
Understanding the transformer architecture proposed in the seminal paper “Attention is all you need”.
After putting it off for some time, I decided to finally sit down and dig into the technical underpinnings of Large Language Models (e.g. ChatGPT). Mostly for myself, but if someone else finds it useful then what the hell.
I set off with the following guiding questions:
- What was the historical context when this groundbreaking paper emerged?
- What was the goal of the paper?
- What is the transformer architecture?
- What does the training process look like?
- What does the inference process look like?
Historical context
The transformer architecture was designed by researchers at Google to address the biggest limitation in the dominant translation models of the time.
Recurrent Neural Networks and their variants were designed to process sequential data by maintaining a form of memory over the elements they had already processed. However, they had a significant limitation: their inherently sequential nature. This constraint meant that each step in a sequence needed to be processed one after another, which limited the ability to parallelize operations.
This sequential processing not only led to longer training times but also made it challenging to capture long-range dependencies in longer sequences, a crucial aspect in tasks like translation.
Goal of paper
The objective was to outperform existing RNN models in language translation by introducing a highly parallelizable model. The Transformer achieves this with "self-attention" processing input sequences in their entirety at once, thereby expediting training and enabling scalability for complex, larger datasets. This architecture, tested using the WMT 2014 English-to-German and English-to-French benchmark datasets, marked a shift from sequential to simultaneous data processing in language models.
Transformer Architecture
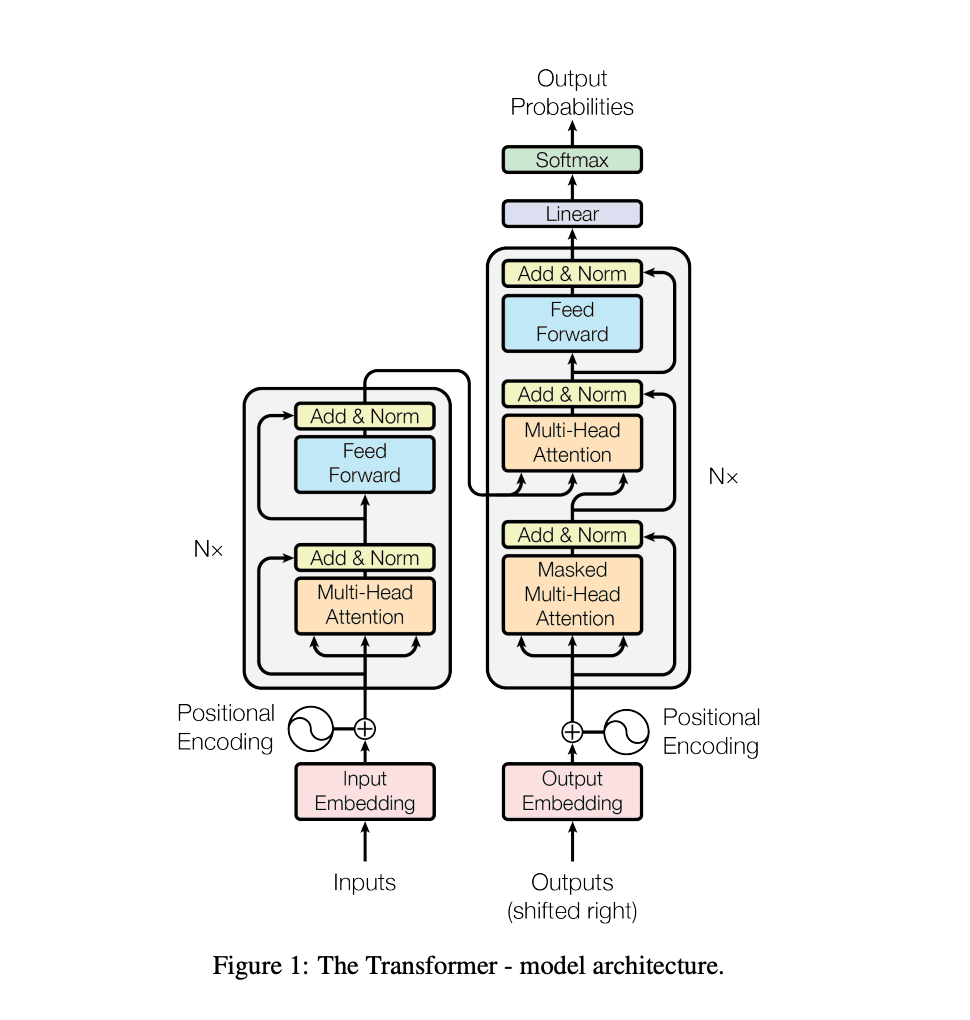
Produce input embeddings for Encoder Stack
- Input Embedding
- Tokenization: The input sequence is tokenized into discrete elements (e.g., words, subwords, or characters).
- Embedding: Each token is mapped to a high-dimensional vector using the embedding matrix. This matrix is part of the model's trainable parameters.
- Positional Encoding
- Encoding: Positional encodings are added to the embedded tokens to retain the order information of the sequence since the self-attention mechanism does not have any inherent notion of sequence position.
- Combination: The positional encodings are combined with the token embeddings to produce position-aware embeddings.
Encoder Processing
- Self-Attention (multi head attention): Each encoder layer computes self-attention for the input tokens. The self-attention mechanism allows each token to interact with every other token in the sequence (relate each token to each other), weighted by the learned attention scores.
- Feed-Forward Network: The output of the self-attention layer is processed through a feed-forward neural network within each encoder layer.
- Residual Connections and Normalization: Each sub-layer (self-attention and feed-forward) in the encoder includes a residual connection followed by layer normalization. These steps are critical for stabilizing the training of deep networks.
Decoder Processing
- Target Embedding: The target sequence (shifted right to predict the next token) is also tokenized, embedded, and added to positional encodings.
- Masked Self-Attention: The decoder's first sub-layer is a masked self-attention layer, which prevents positions from attending to subsequent positions to ensure predictions are based only on known outputs.
- Encoder-Decoder Attention: Each decoder layer also contains an encoder-decoder attention layer that helps the decoder focus on relevant parts of the input sequence. The queries come from the previous decoder layer, and the keys and values come from the output of the encoder.
- Feed-Forward Network: The output of the encoder-decoder attention layer is processed through the decoder's feed-forward neural network.
- Residual Connections and Normalization: Similar to the encoder, each sub-layer in the decoder includes a residual connection followed by layer normalization.
Output Prediction
- Linear Transformation: The decoder's output is transformed by a linear layer to match the size of the output vocabulary.
- Softmax: A softmax layer converts the logits to probabilities, representing the model's prediction for the next token in the sequence
Loss Computation and Backpropagation
- Loss Computation: The predicted probabilities are compared to the actual target sequence using a loss function, typically cross-entropy loss.
- Backpropagation: The gradients of the loss are calculated with respect to all the weights in the model.
- Weight Updates: Using an optimizer like Adam, the model's weights are updated to minimize the loss.
Iteration
- Repetition: This process is repeated for many iterations over the dataset, with the model's predictions and weights being refined each time to improve performance on the training data.
What does the training process look like?
- Cataloging and Gathering Data: This is the initial stage where relevant data is collected. For language models, this means compiling a large dataset of text that the model will learn from.
- Pre-training: During pre-training, the model is exposed to this data and learns to predict parts of the text given other parts. This is where it picks up on language patterns, grammar, and information from the data without any specific task in mind.
- Fine-tuning: After pre-training, the model is further trained on a smaller, task-specific dataset. This helps the model adapt its broad language understanding to perform specific tasks like translation, question-answering, or text summarization.
- RLHF: Stands for Reinforcement Learning from Human Feedback. This is a more advanced training process where the model is refined based on feedback from human trainers. The model makes predictions, humans provide corrections or approvals, and the model learns from these interactions to align its outputs more closely with human judgments or desired outcomes.
- Evals: Conducted using a test dataset, which is a collection of data the model has never seen before. This ensures that the evaluation reflects the model's ability to generalize to new data, rather than just repeating what it has learned by rote. The model's output is compared against the expected output using specific metrics. For language models, common metrics include BLEU for translation accuracy, ROUGE for summarization quality, or accuracy and F1 score for classification tasks.
What does the inference process look like?
- Input Preparation: Just like during training, the input data (such as a sentence needing translation) is tokenized into discrete elements and converted into numerical representations through embedding.
- Positional Encoding: The numerical representations are then combined with positional encodings to maintain the order of the sequence, which is crucial for the model to understand the context and structure of the input data.
- Model Prediction: The prepared input is fed into the trained model. The Transformer processes this input through its encoder and decoder structures using attention mechanisms to weigh the importance of different parts of the input data.
- Generating Output: The decoder generates the output sequence step-by-step, often using techniques like beam search to improve the quality of the output by considering multiple possible sequences and choosing the one with the highest probability.
- Output Processing: The numerical output from the decoder is converted back into a human-readable format, such as the translated text in the target language. This is typically done by mapping the numerical predictions back to words or tokens.
- Post-processing: Sometimes, additional steps like correcting grammar, ensuring coherence, or adjusting style are applied to refine the generated output.
Sources / Resources